Apache Sqoop is the one of the primary frameworks which has been widely used as it is a part of Hadoop ecosystem and has been very dominant for this capability. Apache Sqoop is one of the main technologies used to transfer data to and from structured data stores such as RDBMS and traditional data warehouses to Hadoop. Apache Hadoop finds it very hard to talk to these traditional stores and Sqoop helps to do that integration very easily. Sqoop helps in bulk transfer of data from these stores also integrates easily with Hadoop based systems like Apache Oozie, Apache HBase and Apache Hive.
Apache Sqoop could be employed for many of the data transfer requirement in a Data Lake, which does have HDFS as the main data storage for incoming data from various systems. Below points gives some of the cases where Apache Sqoop makes more sense:
- For regular batch and micro-batch to transfer data to and from RDBMS to Hadoop (HDFS/Hive/HBase), use Apache Sqoop. Apache Sqoop is one of the main and widely used technology in the data acquisition layer.
- For transferring data from NoSQL data stores like MongoDB and Cassandra into Hadoop file system.
- Enterprises having good amount of applications whose stores as based on RDBMS, Sqoop is a best option to transfer data into Data Lake.
- Hadoop is a de-facto standard for storing massive data. Sqoop allows to transfer data easily into HDFS from traditional database with ease.
- Use Sqoop when batch processing is acceptable and performance is required as it is able to split and parallelize data transfer.
- Sqoop has concept of connectors and if your enterprise has diverse business applications with different data stores, Sqoop is an ideal choice.
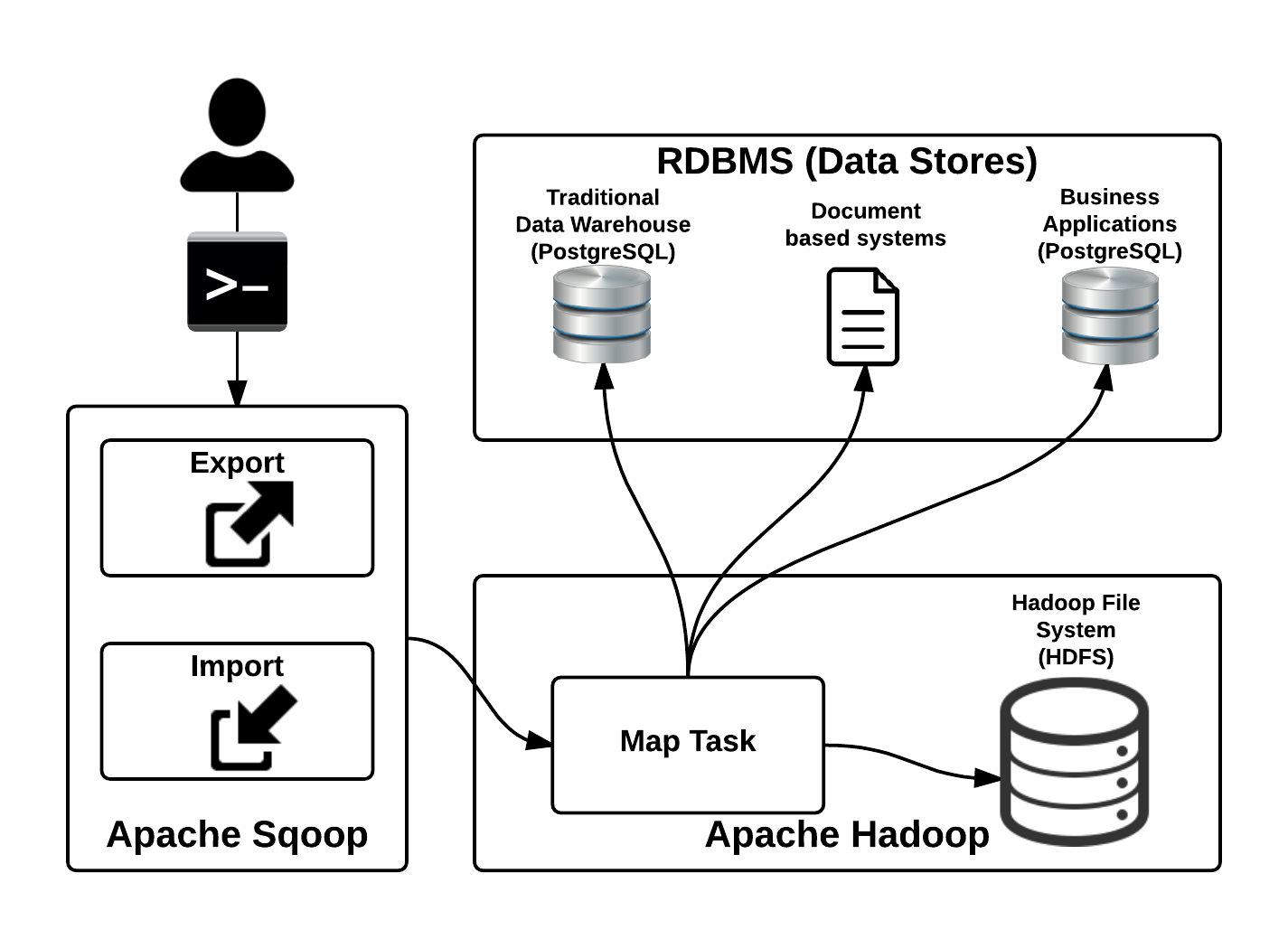
Figure: Capability of Apache Sqoop in a Data Lake
Chapter 5 in the book “Data Lake for Enterprises” covers both theoretical and coding aspect of Apache Sqoop in purview of developing an Enterprise grade Data Lake.
More details on book can be found here.
Page Visitors: 882
Tomcy John
Latest posts by Tomcy John (see all)
- A Guide to Continuous Improvement for Architects - February 2, 2023
- Cloud-first Architecture Strategy - January 26, 2023
- Architecture Strategy and how to create One - January 24, 2023