Chapter 6 in the book “Data Lake for Enterprises” aims to cover another technology being used in the Data Acquisition layer namely Apache Flume. After reading this chapter you will have clear idea on Flume usage in the architecture and also would have gained enough details on full working of Flume. You would also have hands on working with Flume and would also have progressed further in our journey to implement Data Lake and realize the Single Customer View (SCV) use case.
Stream data are the data which are generated by a variety of business application and external application (these days almost all social sites) continuously and in fast pace, usually having a small payload. These are real time data which comes one after the other and makes sense when processed in a sequential manner. For an enterprise analysing these data and then responding appropriately can be a business model and this can indeed transform their way of working. Looking at these data in real time fashion and then personalizing according to customer needs can indeed be very rewarding for the customer, but will also bring financial gains to the business and can also increase customer experience (intangible benefits).
Conceptual view of working of Flume is as shown in the below figure.
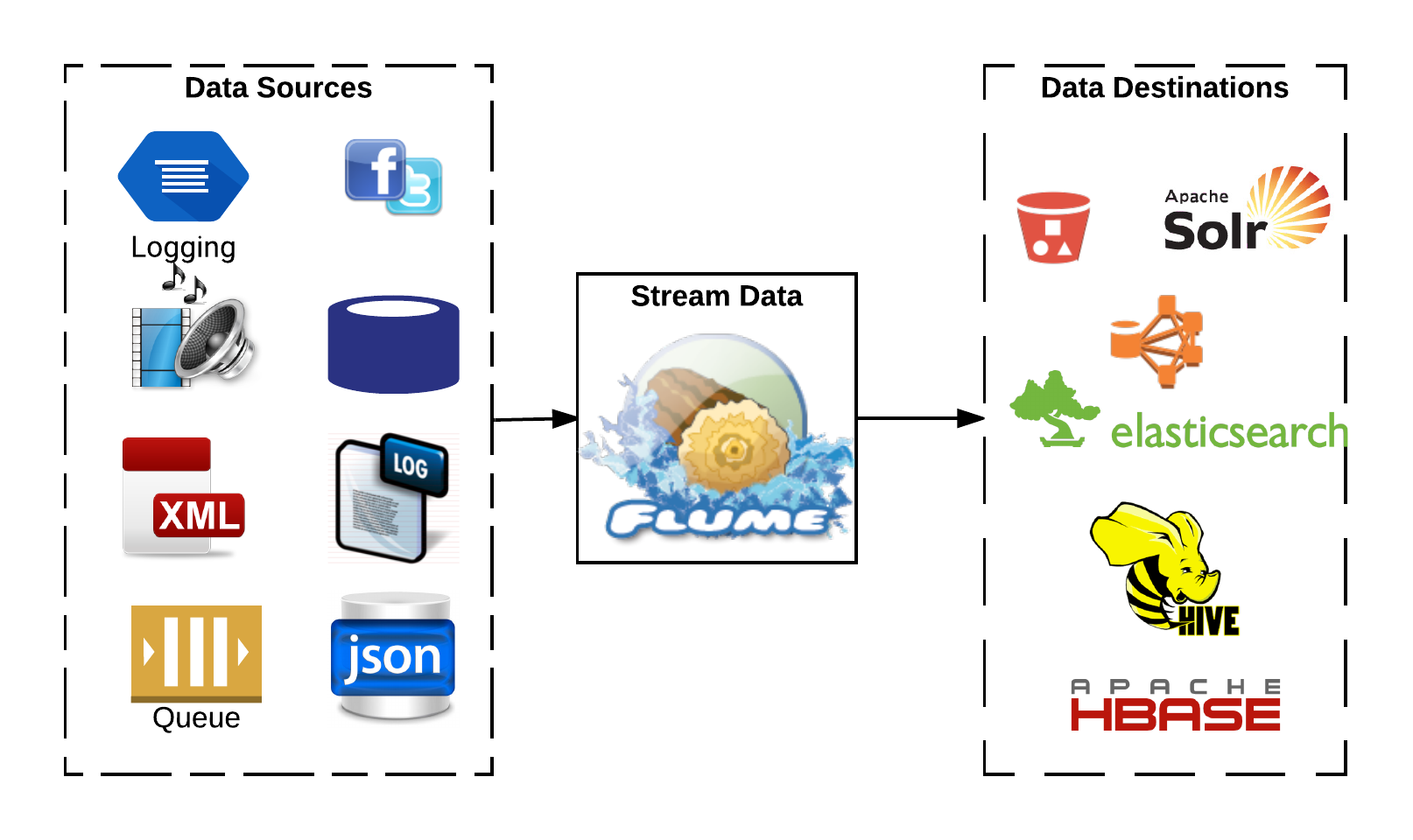
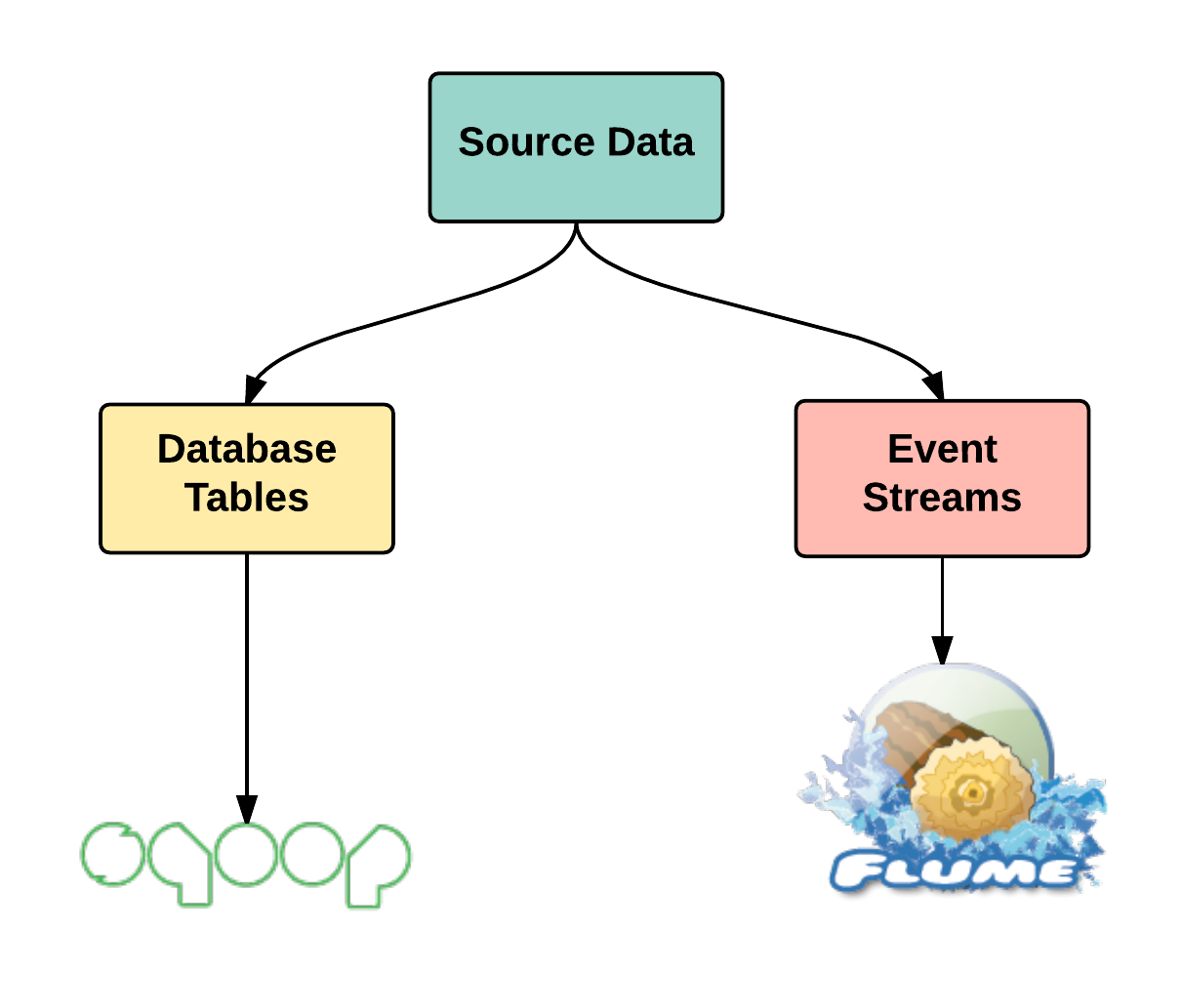
Apache Flume is a very important component in our Data Lake implementation and the main difference between Sqoop and Flume is as shown in the figure below.
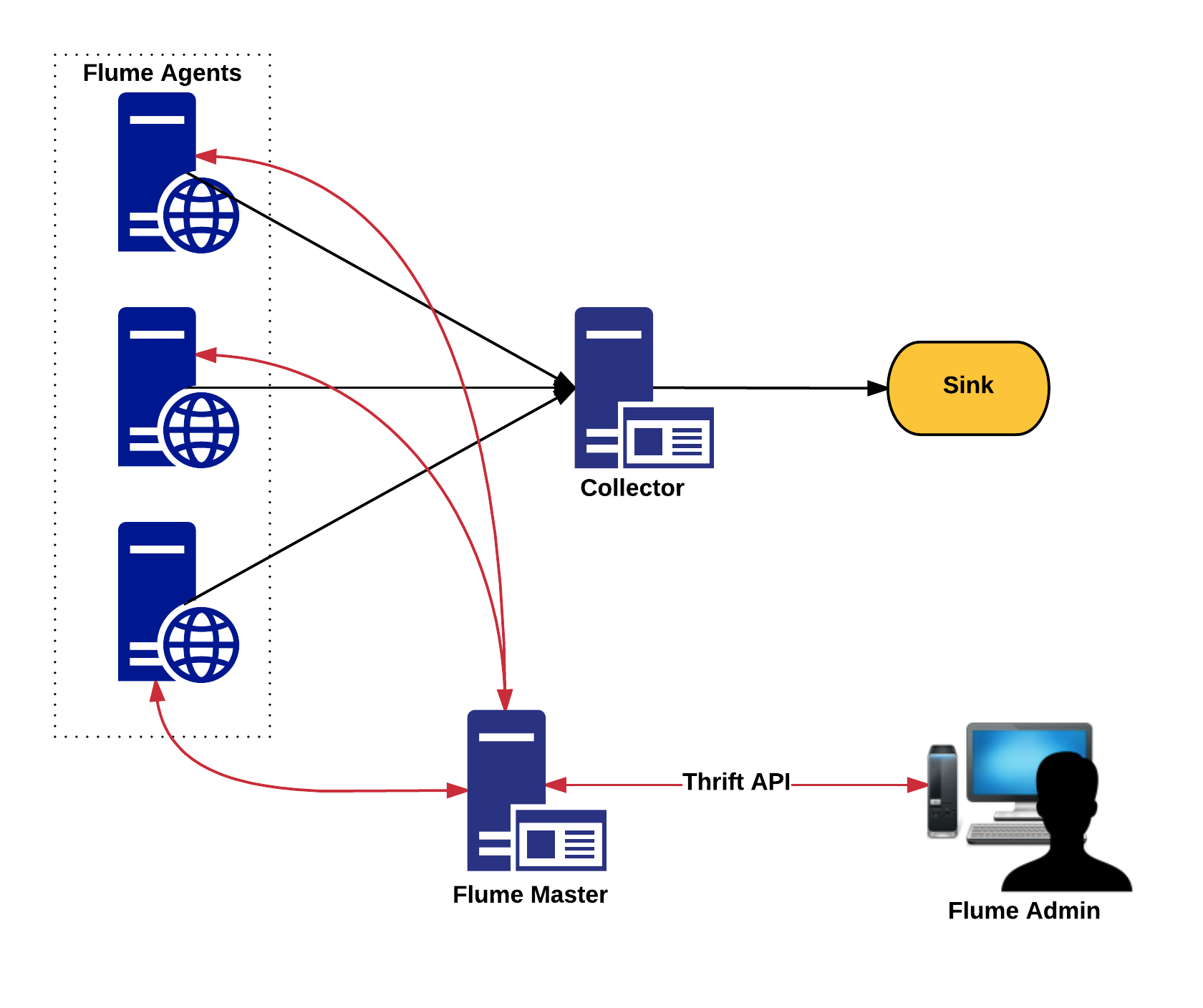
Below figure shows how an advanced Flume architecture would look like in purview of a Data Lake for an enterprise.
More details on book can be found here.
Share the post and help spread the word/work if you like it in as many social channels possible… 🙂
Thanks in advance
One of the co-authors of the book “Data Lake for Enterprises”.
Page Visitors: 574