Disclaimer: I am one of the authors of the book, Data Lake for Enterprises. This article aims at giving first hand information on this book.
More details on the book can be found in here.
If you would like to buy the book, please follow the below links:
In this article by Tomcy John, Pankaj Misra, the authors of the book, Data Lake For Enterprises, we will learn about how the data in landscape of Big Data solutions can be made in near real time and certain practices that can be adopted for realizing Lambda Architecture in context of Data Lake.
The concept of a Data Lake in an enterprise was driven by certain challenges that Enterprises were facing with the way the data was handled, processed and stored. Initially all the individual applications in the Enterprise, via a natural evolution cycle, started maintaining huge amounts of data into themselves with almost no reuse to other applications in the same Enterprise. These created information silos across various applications. As the next step of evolution, these individual applications started exposing this data across the organization as a data mart access layer over central data warehouse. While Data Mart solved one part of the problem, other problems still persisted. These problems were more about data governance, data ownership, data accessibility which were required to be resolved so as to have better availability of enterprise relevant data. This is where a need was felt to have Data Lakes, that could not only make such data available but also could store any form of data and process it so that data is analyzed and kept ready for consumption by consumer applications. In this chapter we will look at some of the criticals aspects of a Data Lake and understand why does it matter for an Enterprise.
If we need to define the term Data Lake, it can be defined as a vast repository of variety of enterprise wide raw information that can be acquired, processed, analyzed and delivered. The information thus handled could be any type of information ranging from structured, semi-structured data to completely unstructured data. Data Lake is expected to be able to derive Enterprise relevant meaning and insights from this information using various analysis and machine learning algorithms.
Lambda Architecture and Data Lake
Lambda Architecture as a pattern provides ways and means to perform highly scalable, performant, distributed computing on large sets of data and yet provide consistent (eventually) data with required processing both in batch as well as in near real time. Lambda architecture defines ways and means to enable scale out architecture across various data load profiles in an enterprise, with low latency expectations.
The architecture pattern became significant with the emergence of big data and enterprise’s focus on real-time analytics and digital transformation. The pattern named Lambda (symbol λ) is indicative of a way by which data comes from two places (Batch and Speed – the curved parts of the Lambda Symbol) which then combines and served through the serving layer (the line merging from the curved part)
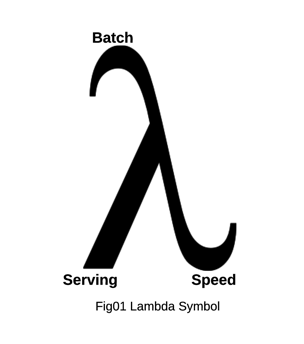
The main layers constituting the Lambda layer are shown below.

In the above high level representation, data is fed to both the batch and speed layer. The batch layer keeps producing and re-computing views at every set batch interval. The speed layer also creates the relevant real-time/ speed views. The serving layer orchestrates the query by querying both the batch and speed layer, merges it and sends the result back as results.
A practical realization of such a Data Lake, can be illustrated as shown below. The figure below shows multiple technologies used for such a realization, however once the data is acquired from multiple sources and queued in messaging layer for ingestion, the Lambda architecture pattern in form of of ingestion layer, batch layer and speed layer springs into action.

Figure 03: Layers in Data Lake
- Data Acquisition Layer
In an organization, data exists in various forms which can be classified as structured data, semi-structured data or as unstructured data.
One of the key roles expected from the acquisition layer is to be able convert the data into messages that can be further processed in a data lake, hence the acquisition layer is expected to be flexible to accommodate variety of schema specifications at the same time must have a fast connect mechanism to seamlessly push all the translated data messages into the data lake. A typical flow can be represented as shown below.
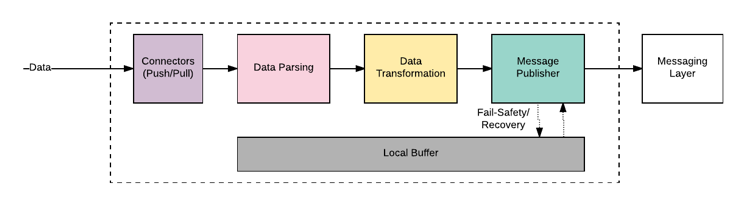
Figure 04: Data Acquisition Layer
- Messaging Layer
The messaging layer would form the Message Oriented Middleware (MOM) for the data lake architecture, and hence would be the primary layer for decoupling the various layers with each other, but with guaranteed delivery of messages.
The other aspect of a messaging layer is its ability to enqueue and dequeue messages, as is the case with most of the messaging frameworks. Most of the messaging frameworks provide enqueue and dequeue mechanisms to manage publishing and consumption of messages respectively. Every messaging frameworks provides its own set of libraries to connect to its resources(queues/topics).
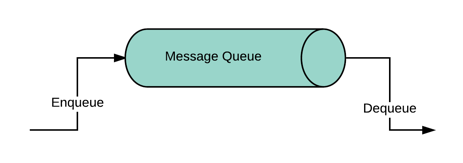
Figure 05: Message Queue
Additionally the messaging layer also can perform the role of data stream producer which can converted the queued data into continuous streams of data which can be passed on for data ingestion.
- Data Ingestion Layer
A fast ingestion layer is one of the key layers in Lambda Architecture pattern. This layer needs to ensure how fast can data be delivered into working models of Lambda Architecture. The data ingestion layer is responsible for consuming the messages from the messaging layer and perform the required transformation for ingesting them into the lambda layer (batch and speed layer) such that the transformed output conforms to the expected storage or processing formats.
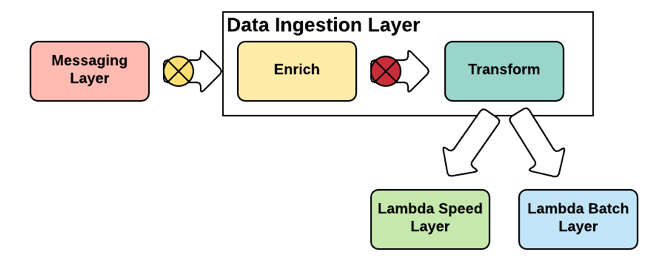
Figure 06: Data Ingestion Layer
- Batch Processing
The batch processing layer of Lambda architecture is expected to process the ingested data in batches so as to have optimum utilization of system resources, at the same time, long running operations may be applied to the data to ensure high quality of data output, which is also known as Modelled data. The conversion of raw data to a modelled data is the primary responsibility of this layer, wherein the modelled data is the data model which can be served by serving layers of Lambda architecture.
While Hadoop as a framework has multiple components that can process data as a batch, each data processing in Hadoop is a map reduce process. A Map and Reduce paradigm of process execution is not a new paradigm, rather it has been used in many application ever since mainframe systems came into existence. It is based on “Divide and Rule” and stems from the traditional multi-threading model. The primary mechanism here is to divide the batch across multiple processes and then combine/reduce output of all the processes into a single output.
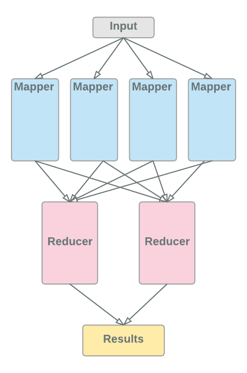
Figure 07: Batch Processing
- Speed (Near Real Time) Data Processing
This layer is expected to perform near real time processing on data received from ingestion layer. Since the processing is expected to be in near real time, such data processing will need to be quick, fast and efficient, with support and design for high concurrency scenarios and eventually consistent outcome. The real-time processing was often dependent on data like the look-up data and reference data, hence there was a need to have a very fast data layer such that any look-up or reference data does not adversely impact the real-time nature of the processing. Near real time data processing pattern is not very different from the way it is done in batch mode, but the primary difference being that the data is processed as soon as it is available for processing and does not have to be batched, as shown below.
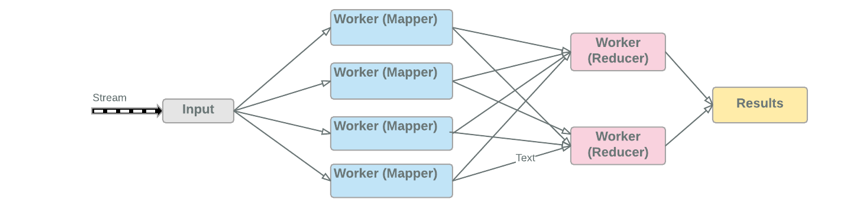
Figure 08: Speed (Near Real Time) Processing
- Data Storage Layer
The data storage layer is very eminent in the Lambda Architecture pattern as this layer defines the reactivity of the overall solution to the incoming event/data streams. The storage, in context of Lambda architecture driven data lake can be classified broadly into non-indexed and indexed data storage. Typically, the batch processing is performed on non-indexed data stored as data blocks for faster batch processing, while speed (near real time processing) is performed on indexed data which can be accessed randomly and supports complex search patterns by means of inverted indexes. Both of these models are depicted below.

Figure 09: Non-Indexed and Indexed Data Storage Examples
Lambda In Action
Once all the layers in lambda architecture have performed their respective roles, the data can be exported, exposed via services and can be delivered through other protocols from the data lake. This can also include merging the high quality processed output from batch processing with indexed storage, using technologies and frameworks, so as to provide enriched data for near real time requirements as well with interesting visualizations.
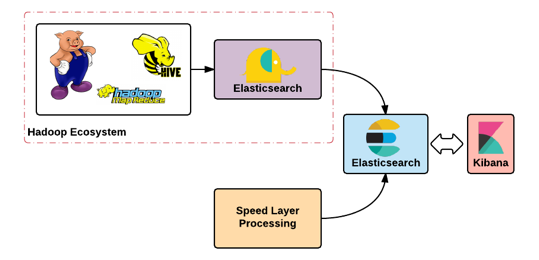
Figure 10: Lambda in action
Summary
In this article we have briefly discussed a practical approach towards implementing a Data Lake for Enterprises by leveraging Lambda architecture pattern
Page Visitors: 1191
Tomcy John
Latest posts by Tomcy John (see all)
- A Guide to Continuous Improvement for Architects - February 2, 2023
- Cloud-first Architecture Strategy - January 26, 2023
- Architecture Strategy and how to create One - January 24, 2023